




この記事では、こんな悩みを解決します。
- 機械学習のモデルの要因を分析するのにいい方法は?
- shapの使い方を知りたい
- shapley値とは?
機械学習のモデルの要因を分析したいってことありますよね。
例えば、お客様に納品した機械学習モデルがなぜこのような結果を出力するのか?を説明しなくてはならない。
という場面。
こんな場面で活躍するのがshapです。
こんな風に作ったモデルが、何を要因として、そのような判断をしたのか?を可視化してくれます。
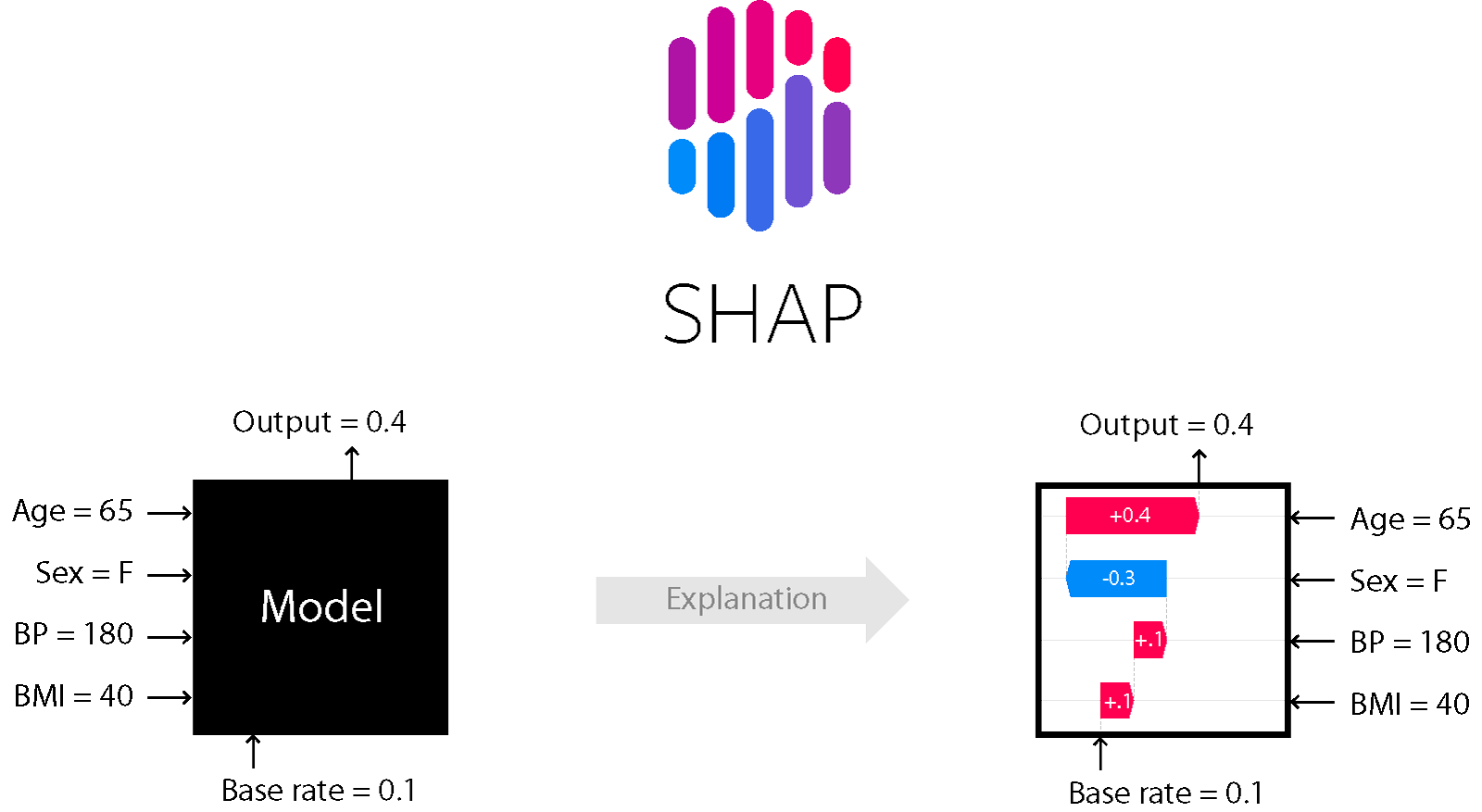
そんな、shapの使い方を見ていきましょう。
☆今だけの激熱キャンペーンをまとめました☆

shapとは?
SHAP(SHapley Additive exPlanations)は、機械学習モデルの出力を説明するためのゲーム理論的アプローチです。
中々難しいのですっとばします。
もし、詳細を知りたい方は、こちらの論文を参照されるのが良いかと思います。

時間があるとき、私も読んでみようと思います。
shapのインストール方法

インストール方法は二つあります。
以下のコマンドをMacならばターミナルで、Windowsならばコマンドプロンプトに打ち込むことで、インストール可能です。
pip install shapもしくはこちらです。
conda install -c conda-forge shapシャープレイ値を持つ説明可能なAI

シャープレイ値とは?
それぞれの因子が提携し、得られた報酬配するような状況において、貢献度が異なる場合どのように構成に分配するかを決めるパラメータの例として、シャープレイ値が存在します。
シャープレイ値を体感する
とりあえず実装しながら、理解を深めましょう。
線形回帰モデルにて、シャープレイ値がどのように機能するのか?を確認します。
今回は、ボストンの住宅価格のデータセットを使用します。
ボストン住宅価格データセット

ボストンの住宅価格のデータセットの説明因子一覧はこちら。
- CRIM-町ごとの一人当たりの犯罪率
- ZN-25,000平方フィートを超える区画にゾーニングされた住宅用地の割合。
- INDUS-町ごとの非小売業のエーカーの割合。
- CHAS-チャールズ川のダミー変数(路が川に接している場合は1、それ以外の場合は0)
- NOX-一酸化窒素濃度(1000万分の1)
- RM-住居あたりの平均部屋数
- 年齢-1940年より前に建設された持ち家の割合
- DIS-5つのボストン雇用センターまでの加重距離
- RAD-放射状高速道路へのアクセシビリティの指標
- TAX-全額固定資産税-10,000ドルあたりの税率
- PTRATIO-町別の生徒と教師の比率
- B-1000(Bk-0.63)^ 2ここで、Bkは町ごとの黒人の割合です
- LSTAT-人口のステータスが%低い
- MEDV-1000ドルの持ち家の中央値
この説明因子から、住宅の価格を推定するというものです。
まずはさくっと、sklearnで、線形回帰モデルにフィッティングします。
import pandas as pd
import shap
import sklearn
# a classic housing price dataset
X,y = shap.datasets.boston()
X100 = shap.utils.sample(X, 100) # 100 instances for use as the background distribution
# a simple linear model
model = sklearn.linear_model.LinearRegression()
model.fit(X, y)Xの中身を確認するとこんなかんじ

EDA
ざくっと、各説明因子と目的関数の関係をプロットして把握しましょう。
import seaborn as sns
df = X
df["cost"] = y
sns.pairplot(df)seabornのペアプロットを使います。
一つのpandasデータフレームにまとめて、目的変数の住宅価格は、costというカラムに格納しました。

わかりにくいですが、一番下の行が、縦軸costと横軸に各因子をプロットしたものです。
横軸:RMの場合には、右肩上がり、
横軸:LSTATの場合には右肩下がりの関係になっていることがわかります。
モデル係数
線形回帰の場合は、その係数を把握すると各説明因子の変動でどれだけ、目的変数が変動するかを把握できます。
print("Model coefficients:\n")
for i in range(X.shape[1]):
print(X.columns[i], "=", model.coef_[i].round(4))結果はこちら。

RMやCHASやDISあたりの変動で目的変数が大きく動くということがわかります。
ただし、注意が必要なのが、この値の大きさが、全体の特徴を反映しているわけではないということです。
あくまで、この値が変動したときに、目的変数がどの程度動くかという指標なのです。
- モデル係数は、各因子がどの程度重要なのか?に対する良い尺度であるわけではないということが重要です。
各因子のモデル出力に対する部分的な影響を把握する
shap.plots.partial_dependence(
"RM", model.predict, X100, ice=False,
model_expected_value=True, feature_expected_value=True
)実行結果は、以下です。

このグラフは、横軸にRM、縦軸にモデルの出力値(住宅価格の推定値)となります。
要するに、RMが大きくなれば、住宅価格も上昇傾向にあるということです。
これは、ペアプロットでも確認していますね。
上のプロットの灰色の水平線は、ボストン住宅データセットに適用されたときのモデルの期待値を表しています。
灰色の縦線は、RMの平均値を表します。
またヒストグラムは、RMの度数を表しています。どれだけの数あるかという意味です。
部分相関プロットからのSHAP値の読み取り
部分相関プロットからどのようにshap値を算出するかを確認します。
線形モデルは非常に単純なので、部分的な依存関係プロットからすぐにSHAP値を読み取ることができます。
予測を説明するとき?(?)、特定の機能のSHAP値 ?は、期待されるモデル出力と、特徴量での部分依存プロットとの差となります。
以下のコードでは18番目のデータのshap値をプロットするコードです。
X.loc[18]18番目のデータはこのようになっています。

# compute the SHAP values for the linear model
explainer = shap.Explainer(model.predict, X100)
shap_values = explainer(X)
# make a standard partial dependence plot
sample_ind = 18
shap.partial_dependence_plot(
"RM", model.predict, X100, model_expected_value=True,
feature_expected_value=True, ice=False,
shap_values=shap_values[sample_ind:sample_ind+1,:]
)赤い線の長さがshap値です。

shap値でプロットすると以下のようになります。
shap.plots.scatter(shap_values[:,"RM"])
シャープレイ値の相加的性質
シャープレイ値の基本的な特性の1つは、すべてのプレーヤー(因子)が存在する場合のゲーム(出力値)の結果と、プレーヤー(因子)が存在しない場合のゲーム(出力値)の結果の差に常に合計されることです。
このアイデアの背景は、協力ゲーム理論からの公正な割り当てからきています。
個々の予測の説明を表示するようにするには、shapのウォーターフォールプロットがあります。
モデルのある出力値がそれぞれの因子がどのように働いているかを示すものです。
このような値(18番目のデータ)を与えたときに、目的変数の値に対して各要素がどの程度作用しているのかを示すウォーターフォールの図となります。
# the waterfall_plot shows how we get from shap_values.base_values to model.predict(X)[sample_ind]
shap.plots.waterfall(shap_values[sample_ind], max_display=14)
期待値から、-3.09分だけRMが作用して、出力値を減らしていることがわかります。
少しずつ、shap値がどのようなものを示し、各因子を説明しているのかが見えてきたと思います。
Pythonによる機械学習やデータ分析
pythonで機械学習やデータ分析を行う上で、shapは非常に協力な武器になります。
その他にも、データ分析には、様々な手法を覚える必要があります。
そこで、おすすめの本を一冊紹介します。
こちらの本では、データ分析の基礎について学ぶことができます。
今回のshapで少し難しいなとか、もっと深くデータ分析を知りたいという方がいらっしゃいましたらこちらの本がおすすめです。
pandas, NunPyといったライブラリの使い方は一通りマスターできます。
今回扱った線形回帰についてもより深く解説されています。

Pythonによるデータ分析の勉強方法が知りたい
そんな方にはこちらの記事がおすすめです。
学習方法を一覧マップにしてあります。
ぜひ参考にしてみてください。
データ分析の勉強方法ってどうしたらいんだろうとか悩んでいる方におすすめです。
まとめ
shapについて解説しました。
shapは、機械学習のモデルの要因を分析したいときに使います。
モデルの予想値を各因子がどのように作用して、出力したのかを可視化することができます。
その背景にある理論は、協力ゲーム理論です。
次の記事は、こちらです。

今回の記事は、以上です。
最後までお読みいただきありがとうございました。


コメント
EDAの個所でdf[“cost”] = yを追加しているので、X.columnsの数が合わず、
以降のモデル係数や部分相関プロットからのSHAP値の読み取りにてcoef_の配列と差が出てしまってエラーが出ます。
df[“cost”] = yをコメント化すればコードは一旦すべて動きましたので共有します。
コメント・共有ありがとうございます。一応私のほうで、動作を確認したつもりでしたが、お手数をおかけし申し訳ござません。