




この記事では、こんな悩みを解決します。
- 機械学習のモデルの要因を分析する良い方法は?
- shapの使い方を知りたい
機械学習のモデルの要因を分析したいってことありますよね。
前回、線形回帰モデルを使って要因を分析する方法を解説しました。
この記事は、こちらの記事の続きです。

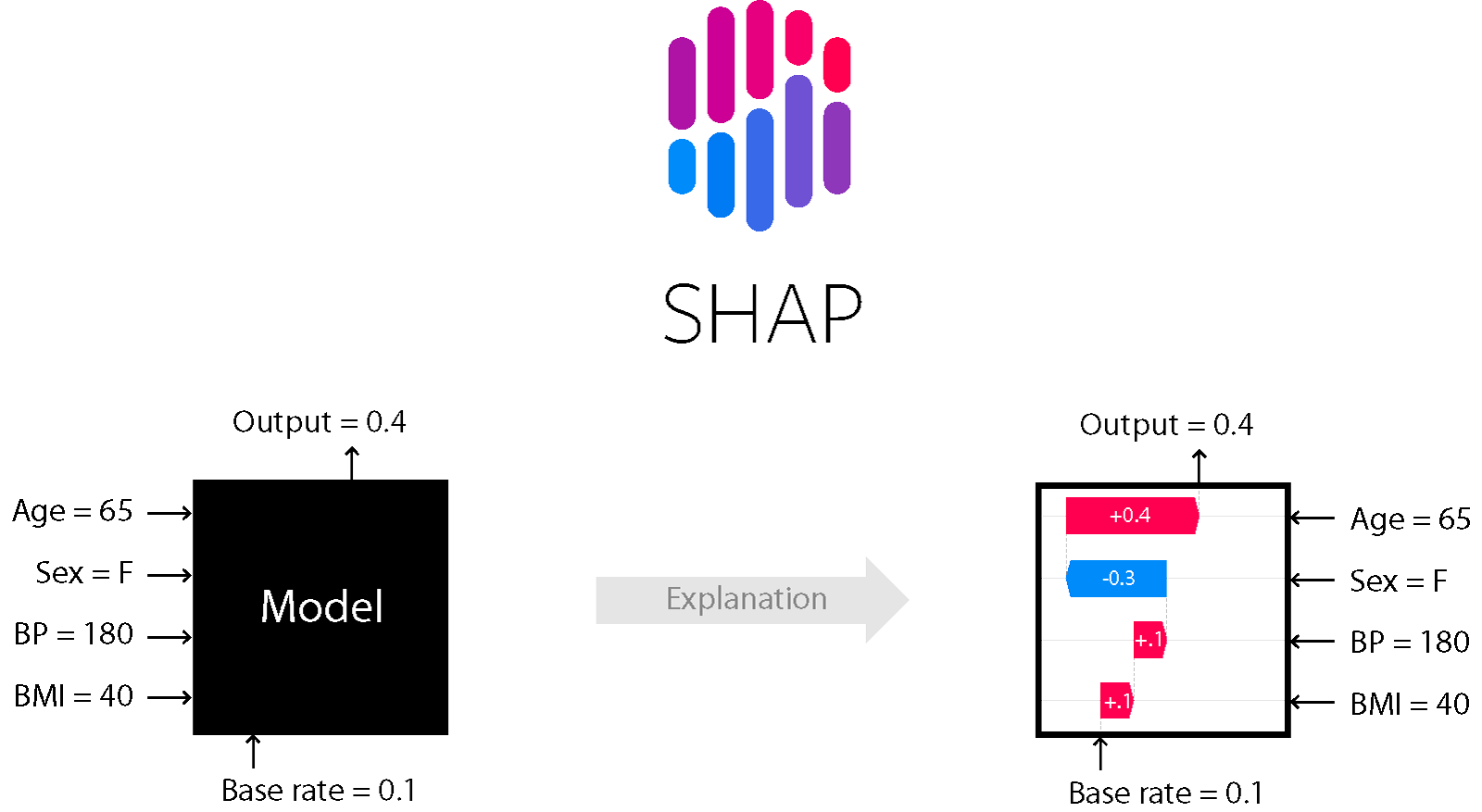
今回は、InterpretMLをつかって、より複雑な機械学習モデルの解釈の方法を解説していきたいと思います。
interpretMLとは?
InterpretMLは、最先端の機械学習の解釈可能性技術のライブラリです。
詳細は、こちらを参照ください。
インストール方法
以下のコマンドをMacならターミナル、Windowsならば、コマンドプロンプトで打ち込んでインストール可能です。
pip install interpretExplainableBoostingRegressorをshapで解析
さてさて早速やっていきます。
このコード単体では、
import pandas as pd
import shap
import interpret.glassbox
# a classic housing price dataset
X,y = shap.datasets.boston()
X100 = shap.utils.sample(X, 100) # 100 instances for use as the background distribution
# compute the SHAP values for the linear model
explainer = shap.Explainer(model.predict, X100)
shap_values = explainer(X)
sample_ind = 18
# fit a GAM model to the data
model_ebm = interpret.glassbox.ExplainableBoostingRegressor()
model_ebm.fit(X, y)
# explain the GAM model with SHAP
explainer_ebm = shap.Explainer(model_ebm.predict, X100)
shap_values_ebm = explainer_ebm(X)
# make a standard partial dependence plot with a single SHAP value overlaid
fig,ax = shap.partial_dependence_plot(
"RM", model_ebm.predict, X, model_expected_value=True,
feature_expected_value=True, show=False, ice=False,
shap_values=shap_values_ebm[sample_ind:sample_ind+1,:])実行結果は、以下です。
赤線の長さが、shap値です。

前回の記事では、線形だったに対し、今回は、非線形になっています。
これは、ExplainableBoostingRegressorによるモデルの出力値になります。
ExplainableBoostingRegressorは、EBMモデルベースの回帰モデルだと思います。(間違ってたら指摘ください。)
EBMは、バギングや勾配ブースティングをベースとしたモデルだと思います。
glassboxとは、因子の解釈を人間にわかるよう可視化できるものを指します。
GAMと呼ばれる加法モデルがあるのですが、短所として、モデルの精度が低くなる傾向があります。
一方で、ランダムフォレストなどの機械学習を用いると精度が上がるものの、ブラックボックス化されがち。
そこで、EBMは、精度をランダムフォレスト並に担保を狙い、glassboxであるということです。

この結果から、公式サイトから参照したものです。
これによれば、EBMの精度が、ランダムフォレストやXGBoostと比較して、もっとも高いということになります。
このモデルをわざわざshapに突っ込んで、解釈しようというのが今回の試みです。
shap値の可視化
shap.plots.scatter(shap_values_ebm[:,"RM"])実行結果は以下です。

ウォータフォール図
18番目のサンプルがどのような解釈で、モデルが出力しているのかを可視化します。
# the waterfall_plot shows how we get from explainer.expected_value to model.predict(X)[sample_ind]
shap.plots.waterfall(shap_values_ebm[sample_ind], max_display=14)
shap値の貢献度を確認
# the waterfall_plot shows how we get from explainer.expected_value to model.predict(X)[sample_ind]
shap.plots.beeswarm(shap_values_ebm, max_display=14)実行結果は以下です。
横軸が目的変数の値、縦軸が説明因子の貢献度の高さです。
例えば、LSTATはで考えます。
目的因子が、正の値を取るとき、LSTATは値がブルーになっています。
ブルーは低い値を指します。
つまり、目的変数が高くなると、説明変数の値は下がる。
負の相関ということです。

上の因子ほど貢献度合いが高い因子を示します。
デフォルトでは、各機能のSHAP値の平均絶対値で順番付けされます。
この順序では、幅広い平均的な影響に重点が置かれます。
そこで、個々の人に大きな影響を与える因子を見つけたい場合は、最大絶対値で並べ替えることができます。
その他詳細は、こちら参照ください。
shap.plots.beeswarm(shap_values_ebm, order=shap_values_ebm.abs.max(0),max_display=14)
あれ、LSTATの方がDISより大きい幅な気がするが・・・ちょっとよくわかりません。これは。
まぁざっくりとは、LSTATとRMが大切ということですね。

LSTATと目的変数の関係をみると、確かに負の相関がありそうね。
目的変数を決定する上でshap値の解釈を見ても、貢献度が高いことが伺えます。

RMは目的変数と正の相関がありそう。
目的変数を決定する上でshap値の解釈を見ても、貢献度が高いことが伺えます。
まとめ
今回は、InterpretMLの機械学習モデルの解釈をshapで実施する方法を解説しました。
最後までお読みいただきありがとうございました。


コメント
[…] shapの使い方|InterpretMLの機械学習モデル(EBM)の解釈の方法を解説機械学習のモデルの要因を分析する良い方法は? shapの使い方を知りたいtsukimitech.com2021.03.20 […]